大数据实验报告Hadoop编程实现wordcount单词统计程序附源码.doc
”Hadoop大数据 wordcount单词统计 实验报告“ 的搜索结果

1.使用示例程序实现单词统计 (1)wordcount程序 wordcount程序在hadoop的share目录下,如下: 1 2 3 4 5 6 7 8 9 [root@leafmapreduce]#pwd /usr/local/hadoop/share/hadoop/mapreduce [root@leafmapr....

在scala模式下编写单词统计 二、实验过程 了解spark的构成 2、具体步骤 1、打开一个终端,启动hadoop hadoop@dblab-VirtualBox:/usr/local/hadoop/sbin$./start-all.sh 2、启动spark hadoop@dblab-V.....
一、概述单词计数是最简单也最能体现MapReduce思想的程序之一,单词计数的主要功能在于:统计一系列文本文件总每个但系出现的次数。本次实验预通过分析WordCount源码来进一步明确MapReduce程序的基本结构和...
1.单词计数实验(wordcount) (1)输入start-all.sh启动hadoop相应进程和相关的端口号 (2)打开网站localhost:8088和localhost:50070,查看MapReduce任务启动情况 (3)写wordcount代码并把代码生成jar包 (4)运行...


阅读目录一、创建项目 :example-hdfs二、项目目录三、WordCountMapper.class四、WordCountReducer.class五、WordCounfDriver.class六、pom.xml七、打包jar包八、在SecureCRT软件上传刚刚生成的jar包九、运行十、...
大数据词频统计实验报告 文末附github数据及代码,希望各位可以给我提一些建议,也可以对内容展开讨论。 目录 一、实验目标... 2 二、实验设计... 2 1.数据源... 2 2.实验内容... 2 3.代码模块设计... 3 三...
实验标题:①安装Hadoop;②;③;④ ◉ 实验中用到的Linux命令: cd /home/hadoop #把/home/hadoop设置为当前目录 cd .. #返回上一级目录 cd ~ #进入到当前Linux系统登录用户的主目录(或主文件夹)。在 Linux ...
本文出现的错误及解决方法均为亲身经历,太痛苦了....在此将错误整理一下,供...首先hadoop的运行方式分为本地运行和集群运行,本机运行及在本机编写程序后直接执行,集群运行则是将程序写完后打包,上传到hdfs中运行。
实验内容与完成情况: 1. 使用IntelliJ IDEA工具开发WordCount程序 在Linux操作系统中安装IntelliJ IDEA,然后使用IntelliJ IDEA工具开发WordCount程序,并打包成JAR包,提交到Flink中运行。 安装Flink并启动: 安装...
文章目录前言一、启动Hadoop二、环境搭配三、求平均值总结 前言 本文主要是学习MapReduce的学习笔记,对所学内容进行记录。 实验环境: 1.Linux Ubuntu 16.04 2.hadoop3.0.0 3.eclipse4.5.1 一、启动Hadoop 进入...
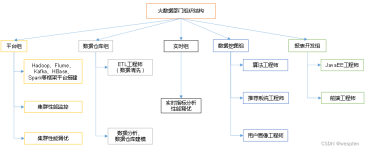
文档基于介绍基于Hadoop的大数据生态圈。介绍下图每一个组件的使用场景及使用方法,同时还对每一个组件有更深入的介绍。 ...
前面已经在我的Ubuntu单机上面搭建好了伪分布模式的HBase环境,其中包括了Hadoop的运行环境。 详见我的这篇博文:http://blog.csdn.net/jiyiqinlovexx/article/details/29208703 我的目的主要是学习HBase,下一步...
package sy; import java.io.IOException; import java.util.Collections; import java.util.Comparator; import java.util.HashMap; import java.util.LinkedList;...import org.apache.hadoop.co.
安装Java环境5.Hadoop 26.Hadoop单机配置(非分布式)7.Hadoop伪分布式配置8.运行Hadoop伪分布式实例三、分布式文件系统HDFS1.利用Shell命令与HDFS进行交互1.1目录操作1.2文件操作2.利用Web界面管理HDFS3.利用Java API...
实验目的利用搭建好的大数据平台 Hadoop,对 HDFS 中的文本文件进行处理,采用 Hadoop Steaming 方式,使用 Python 语言实现英文单词的统计功能,并输出单词统计结果。实验内容将附件"COPYING_LGPL.txt"上传 Hadoop ...
Hadoop调用MapReduce进行词频统计博客目录一.案例1.实验目的2.分析步骤二.前置准备1.传输文本文件2.环境搭建(1)使用VirtualBox虚拟机软件安装Ubuntu(2)在Ubuntu中安装Hadoop和Eclipse三.具体步骤1.下载保存文本文件2...
3. 查看 Hadoop 自带的 MR-App 单词计数源代码 WordCount.java,在 Eclipse 项目 MapReduceExample 下建立新包 com.xijing.mapreduce,模仿内置的 WordCount 示例,自己编写一个 WordCount 程序,最后打包成 JAR ...
实验指导: 5.1 实验目的 基于MapReduce思想,编写WordCount程序。 5.2 实验要求 1.理解MapReduce编程思想; 2.会编写MapReduce版本WordCount; 3.会执行该程序; 4.自行分析执行过程。 5.3 实验原理 ...
《大数据技术基础》实验1-实验7
标签: 大数据
实验内容:根据课本中《大数据架构Hadoop》这一章末尾实验"安装Hadoop"完成实验内容。要求安装采用分布式安装,使用三台虚拟机完成。
利用搭建好的大数据平台 Hadoop,对 HDFS 中的文本文件进行处理,采用 Hadoop Steaming 方式,使用 Python 语言实现英文单词的统计功能,并输出单词统计结果。 实验内容 将附件"COPYING_LGPL.txt"上传 ...

Github源码地址:https://github.com/courseralxy/MapReduce-Big-Data-Processing/tree/master/final%20project ...文字版实验...
WordCount实例是大数据学习过程中的入门,相当于学习各种编程语言时打印“Hello World”的一样。本次实验是通过Java代码来实现的。 数据准备 任意创建一个文本文件,在其中写入一些单词,并用空格隔开。 Mapper...
推荐文章
- 机器学习之超参数优化 - 网格优化方法(随机网格搜索)_网格搜索参数优化-程序员宅基地
- Lumina网络进入SDN市场-程序员宅基地
- python引用传递的区别_php传值引用的区别-程序员宅基地
- 《TCP/IP详解 卷2》 笔记: 简介_tcpip详解卷二有必要看吗-程序员宅基地
- 饺子播放器Jzvd使用过程中遇到的问题汇总-程序员宅基地
- python- flask current_app详解,与 current_app._get_current_object()的区别以及异步发送邮件实例-程序员宅基地
- 堪比ps的mac修图软件 Pixelmator Pro 2.0.6中文版 支持Silicon M1_pixelmator堆栈-程序员宅基地
- 「USACO2015」 最大流 - 树上差分_usaco 差分-程序员宅基地
- Leetcode #315: 计算右侧小于当前元素的个数_找元素右边比他小的数字-程序员宅基地
- HTTP图解读书笔记(第六章 HTTP首部)响应首部字段_web响应的首部内容-程序员宅基地